Automated Hypothesis Formation of Molecular Structures and Interactions Using Physics-Based Modeling and SimulationJuergen Haas and Dimitris N. Metaxas
|
||||||
|
Described below is the development of efficient representational and algorithmic techniques for automating the process of hypothesizing properties of molecules, mechanisms, and pathways in molecular genetics. Physics-based modeling and simulation is used to efficiently utilize structural and physical/chemical information and for visualization and manipulation in a graphical user interface. Abstract reasoning and learning is used for efficient search for configurations that are consistent with the given constraints. Thus our system CASDIM (Computer Aided Scientific Discovery In Molecular Biology) consists of two tightly integrated components: the simulation environment and the learning/reasoning component. We present simulation experiments in CASDIM demonstrating recognition events as part of a hypothetical gene regulation mechanism. IntroductionUnderstanding control and regulation of gene expression remains an important and largely unsolved problem in molecular biology. The complexity of the molecular networks involved in gene regulation is increasingly recognized as more and more experimental data become available on DNA sequences, expression levels, and molecular interactions. Until now, comprehensive hypotheses about molecular mechanisms and networks involved in gene regulation have been formulated exclusively by humans. We are not aware of any software that formulates such hypotheses using physics-based models and simulation, a powerful analysis technique that we believe is similar to the way human biologists often think and reason about biomolecular systems. Problem statementCASDIM deals with biomolecular events such as transcription complex formation or chains of molecular reactions/interactions that lead to the synthesis of protein complexes. Many of these reactions are reversible in a molecular system so that processes can be regulated in response to environmental changes. This means the changes in a molecular system over time are highly sensitive to the initial conditions. Due to incomplete knowledge, the complexity of the molecular system, and the random thermal vibrations it is impossible to precisely specify the initial conditions, and a probabilistic approach has to be taken. Thus the kind of problem solved by CASDIM is described by the following input/output specification: Input: A set of pairs Output: Parameter settings for PS such that simulation leads any initial states consistent with Ii to final states Fi that are consistent with Gi with probability Pi within time Ti. System DescriptionMolecules such as proteins and DNA are modeled as agglomerations of complex three-dimensional polygons. Objects
can be linked to form flexible chains such as biopolymers (DNA, RNA, protein sequences). In order to facilitate
simulation of a large number of molecules, large objects are hierarchically composed from smaller ones whose locations
are specified with respect to the model coordinate system of the large object. Thus, a large molecule can be moved
or rotated simply by moving or rotating its coordinate system. The coordinates of the component objects have to
be dereferenced only if proximity to other objects has been determined. Proximity of objects is efficiently computed
by structuring them in roughly spherical components with precomputed radii. Electrostatic fields are approximated
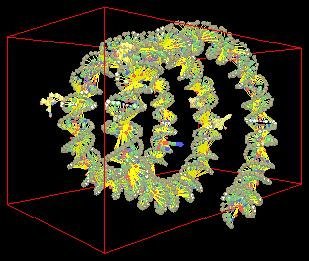
using distributions of point charges of varying strengths. We have devised a procedure for constructing DNA models
that takes as input a sequence of nucleotide names (A,C,G,T) and constructs a corresponding three-dimensional DNA
model including the super-helical structure (see Fig.1). We have implemented a random number generator that generates a distribution of three-dimensional displacements
such that the average displacement is consistent with the Einstein relation. The Box-Muller method is used to obtain
a gaussian distribution. Translocation and rotation of each molecule are determined by diffusion, electrostatic
fields, and collisions. Coulomb's law is used to compute the electrostatic forces that determine the translocations
and rotations: CASDIM will try to determine values for incompletely specified parameters, such that applying simulations to states consistent with the initial state description of each training pair will lead to a final state consistent with the corresponding final state description. In general it will be necessary to run a set of simulations for each training pair and parameter setting, since final state descriptions are typically probabilistic in nature. E.g., a protein may bind to a particular location on the DNA with 80% probability given a certain amount of time. Now, the search strategy for determining consistent parameter settings. At an abstract level, the search for correct parameter settings can be viewed as a set of planning problems. Each training instance specifies (1) a partial initial state description Ii , and (2) a partial goal state description Gi . Such descriptions involve for example specification of concentrations of certain molecules or molecule complexes. The system also has a set of rules of the form (C1--> C2), where C1 (the antecedent) is a set of conditions at time t1 and C2 is a set of conditions at time t2 and t1 < t2. This means that if C1 holds in a state S1, then continuing the simulation will lead to a state S2 in which C2 holds. For example, such rules may specify how the change of concentrations of certain molecules influences the concentrations of other molecules; how binding properties between molecules influence concentrations; how the recognition ability of a protein can be disabled through binding to another molecule; etc. These rules are essentially descriptive abstractions of molecular processes and may be either supplied by the user or inferred by the system. CASDIM uses these rules to compile a plan that leads from the initial state description Ii to the final state description Gi. Such a plan may specify for example that some molecule M1 should bind to another molecule M2. CASDIM would then try to modify M1 and/or M2 by changing parameter values and testing it in the simulation environment to achieve this requirement. In order to obtain a plan for a particular training instance efficiently, CASDIM reasons back from the final state (goal state) description. It searches for rules that achieve (parts) of the goal state description. Then it searches for rules that achieve the antecedents of those rules, etc. until a state description is reached that is consistent with the initial state description. Next, using a special set of rules, parameter settings are determined such that the initial states (in the simulation) are consistent with these refined initial state descriptions. And finally, simulation is used to check if these parameter settings actually lead to the final states specified in the training pairs. Note: All presentations at this site are in abstract format. Feel free to email me for detailed documents. Related Publications"Case-Based Reasoning Driven Gene Annotation," G. Christian Overton and Juergen Haas, book chapter
in: Computational Methods in Molecular Biology, Edited by Steven Salzberg, David Searls, and Simon Kasif Published
by Elsevier Science, 1998. |
||||||